Je vous ai laissés en suspens vendredi dernier en vous promettant une nouvelle visualisation des plus récents sondages. Pour se rafraîchir la mémoire, la marge d’erreur dépend du pourcentage obtenu dans le sondage (elle augmente à mesure qu’il s’approche de 50%) et de la taille de l’échantillon (l’un monte quand l’autre descend), pas de la taille de la population dont on veut connaître l’opinion.
Chose promise, chose due
J’ai refait un graphique similaire à celui de Qc125 (avec les marges d’erreur cette fois) pour les trois derniers sondages du diagramme présenté. J’ai joint le sondage de Forum (effectué le 23 août auprès de 965 personnes) et le dernier Léger (effectué du 24 au 28 août auprès de 1010 personnes)1.
J’ai d’abord tenté de le faire dans Google Spreadsheets, pour que vous puissiez accéder au fichier et vérifier le tout. Toutefois, je n’avais la possibilité que de mettre une barre d’erreur constante ou en pourcentage, or, nous avons vu vendredi que c’était justement un peu plus compliqué que ça.
J’ai aussi essayé avec Excel et son équivalent en logiciel libre LibreOffice pour arriver toujours au même problème: pas moyen de définir une barre d’erreur différente pour chaque point. Ce n’est donc pas surprenant qu’on voit aussi peu de représentations des données de sondage avec leurs marges d’erreur.
J’arrivais réussi à m’en sortir en faisant des graphiques en chandeliers comme on utilise pour représenter l’évolution des cours boursiers, mais Martin trouvait ça laid. Pour plaire donc à la moitié responsable du visuel de notre duo, j’ai donc sorti l’artillerie lourde: j’ai programmé le graphique dans le logiciel libre d’analyse statistique R.
Après plusieurs heures de gossage, ç’a donné ceci2:
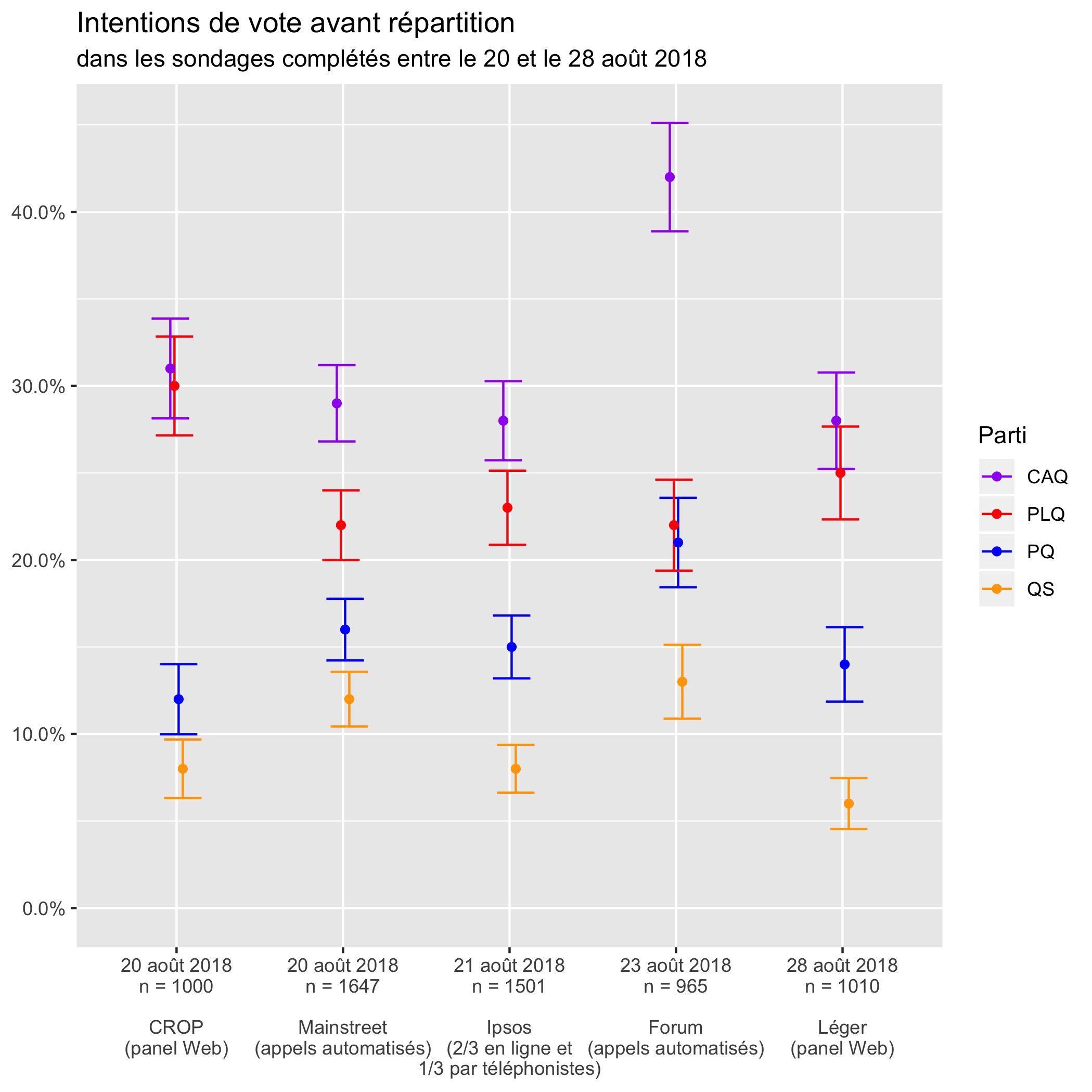
Le point situe le résultat du parti dans le sondage. Le trait vertical, délimité par deux barres horizontales, indique l’intervalle de confiance si on tient compte de la marge d’erreur à 95% (ou 19 fois sur 20). On constate que les traits en haut sont plus longs que les traits en bas. Comme on l’a rappelé au début, la marge d’erreur augmente avec la proportion (ou plutôt sa proximité à 50%).
On voit ainsi en comparant les scores des différents partis verticalement au sein d’un même sondage que:
- dans CROP, la CAQ et le PLQ sont à égalité statistique;
- dans Forum, le PLQ est plutôt à égalité statistique avec le PQ (et la CAQ loin devant);
- dans Léger, les intentions de vote pour la CAQ et le PLQ se chevauchent, donc sont à égalité statistique comme dans CROP.
Différences de mode de collecte de données
Bryan Breguet de Too Close To Call s’est penché jeudi sur les scores qui divergent d’un sondage à l’autre dans un billet intitulé «Québec Solidaire à 8 ou 14%?». Il est troublé par le fait que la divergence suit la différence dans le mode de collecte de données:
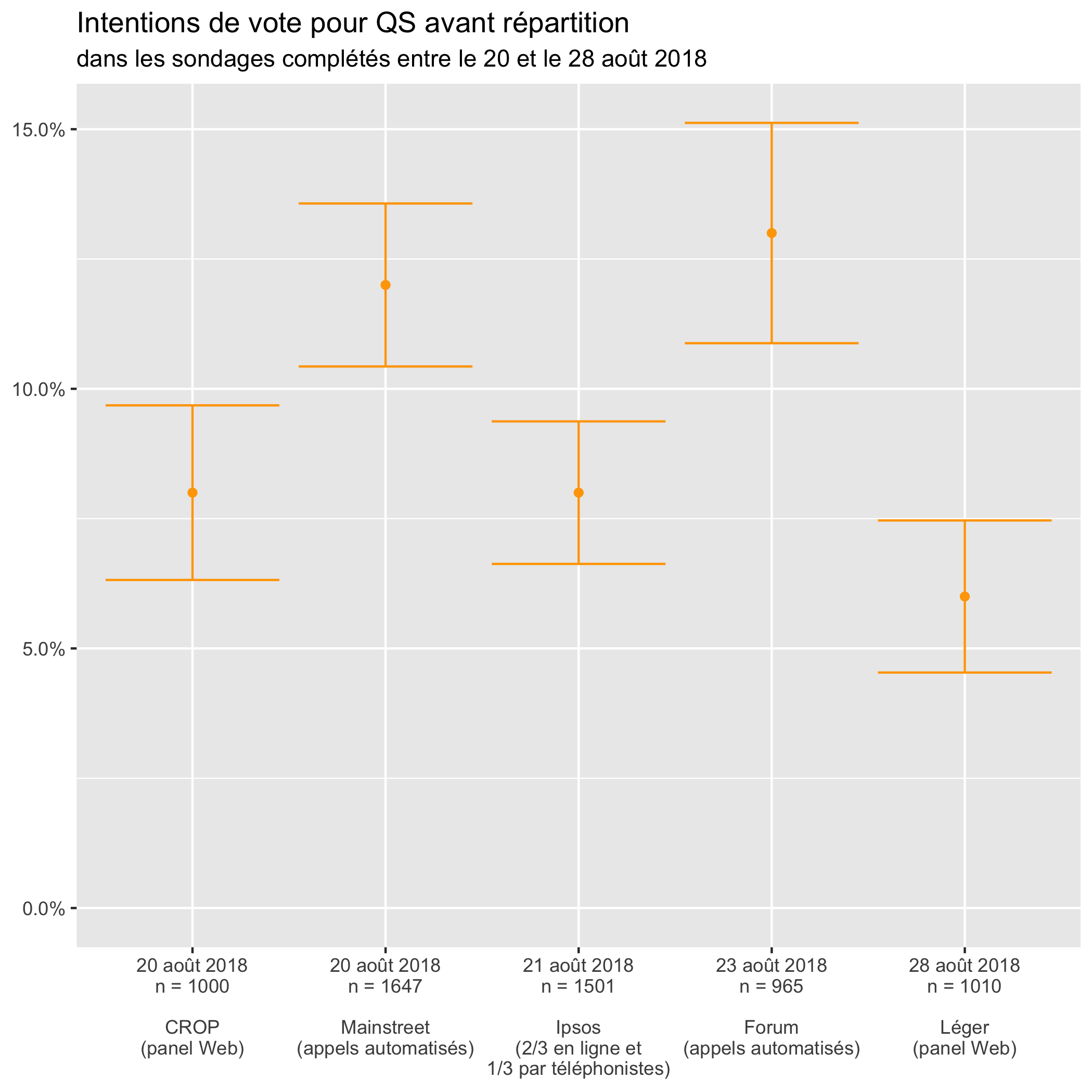
On constate que trois sondages situent le parti sous la barre des 10% et deux, ceux qui sont effectués par appels automatisés, sont au-dessus. Plus important encore: les résultats de ces deux groupes ne se chevauchent pas, même si on tient compte de la marge d’erreur. (Aucune des barres horizontales ne touche à la ligne des 10%.)
Mainstreet et Forum, qui utilisent des appels automatisés, obtiennent donc des résultats significativement plus élevés que CROP et Léger, qui utilisent des panels Web, et Ipsos. Cette dernière firme combine une collecte de données en ligne avec la bonne vieille méthode des êtres humains qui appellent d’autres êtres humains pour leur poser des questions.
Pareil, pas pareil?
Bryan a fait 10000 simulations pour conclure que soit Mainstreet, soit Léger se trompe. Il a supposé que les intentions de vote «réelles» à l’égard de Québec solidaire se situaient à 10%. Il a simulé pour une taille d’échantillon de 1010 personnes sondées, comme dans Léger.
Sur l’axe horizontal, on trouve les intentions de vote de Québec solidaire (centrées à 10% parce que c’est l’hypothèse de départ). Sur l’axe vertical, c’est le nombre de simulations pour lesquelles Québec solidaire obtenait un pourcentage donné.
Distribution de 10000 simulations
avec QS à 10% et une taille d’échantillon de 1010
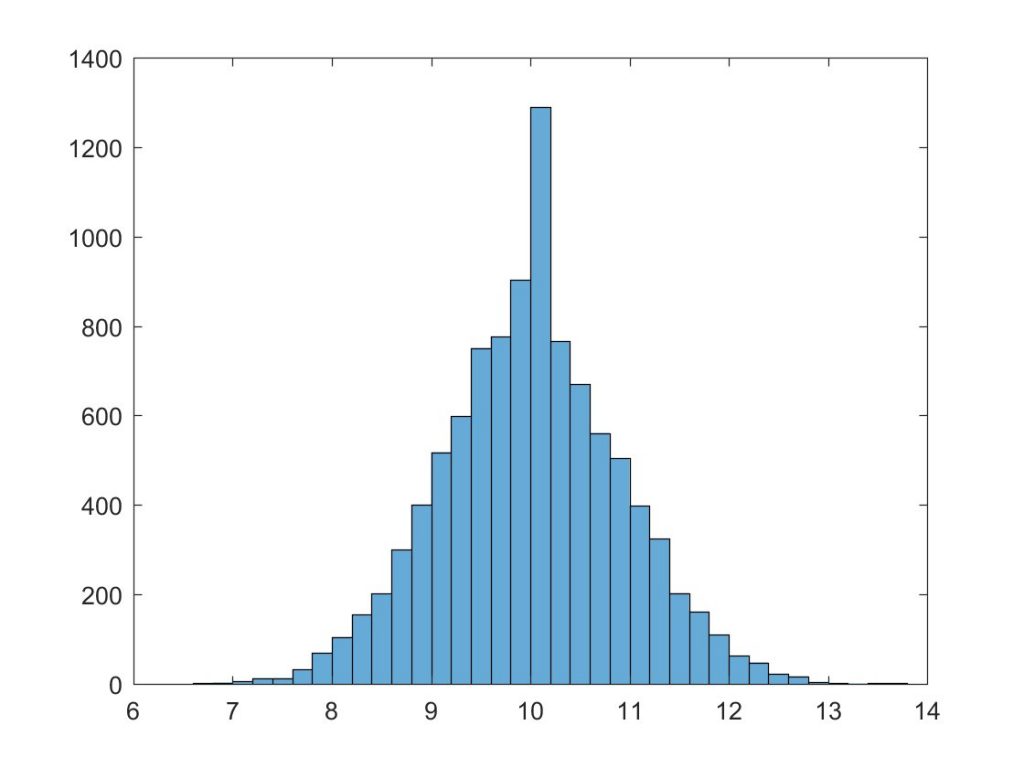
Léger a Québec solidaire à 6%: on voit que très peu de simulations placent le parti de gauche sous les 7%. Pour Mainstreet, Bryan utilise les données des sondages quotidiens (pour lesquels l’accès est payant). Québec solidaire était alors à 13,1% (il a depuis passé la barre des 15%). Encore une fois, à peu près aucune simulation n’obtenait des résultats aussi hauts.
Un effet que sur les intentions de vote pour Québec solidaire
Si on regarde les résultats pour les autres partis, on constate qu’il n’y a pas de biais systématique en fonction du mode de collecte des données.
Forum (qui utilise des appels automatisés) place la Coalition avenir Québec et le Parti québécois loin devant les autres, au-delà des marges d’erreur.
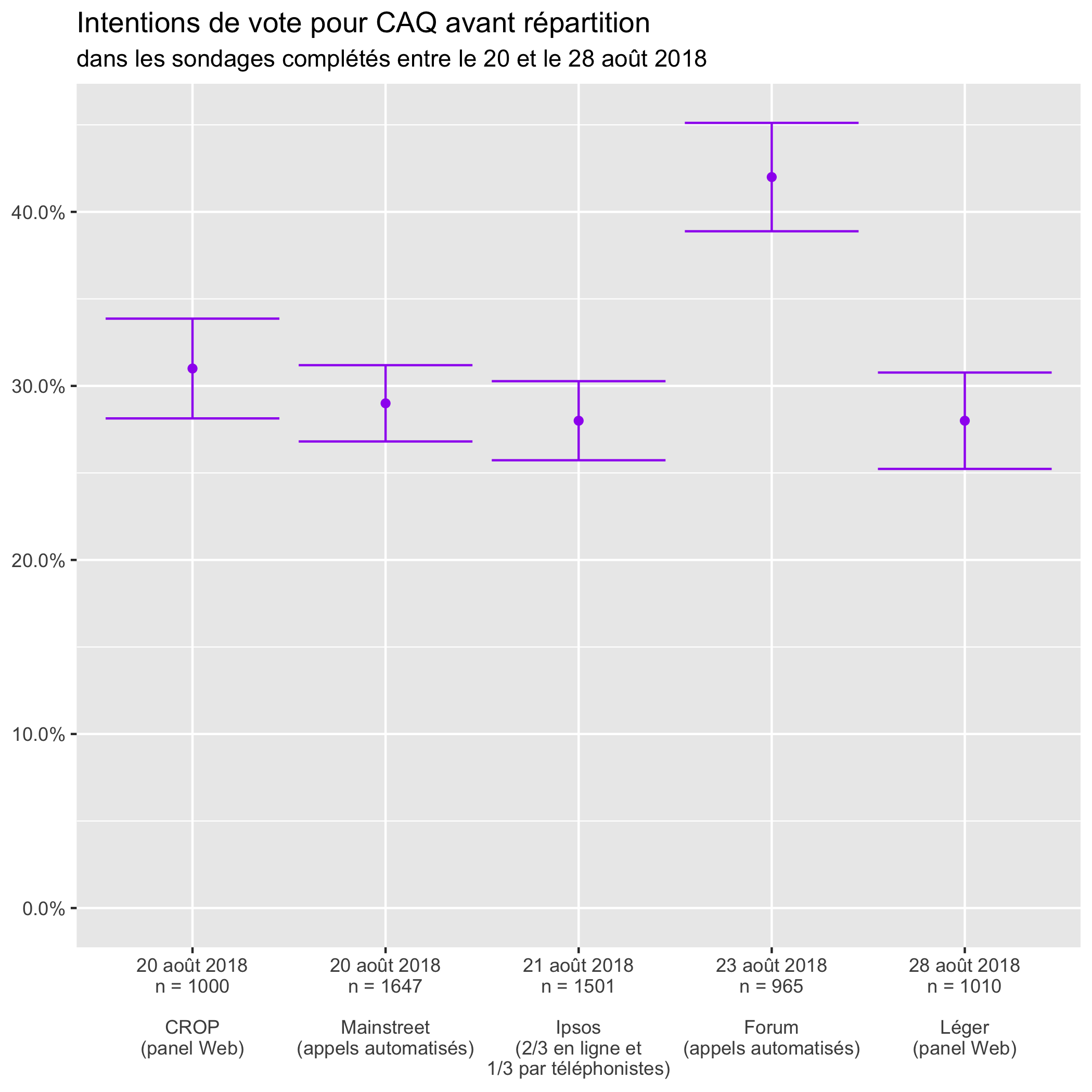
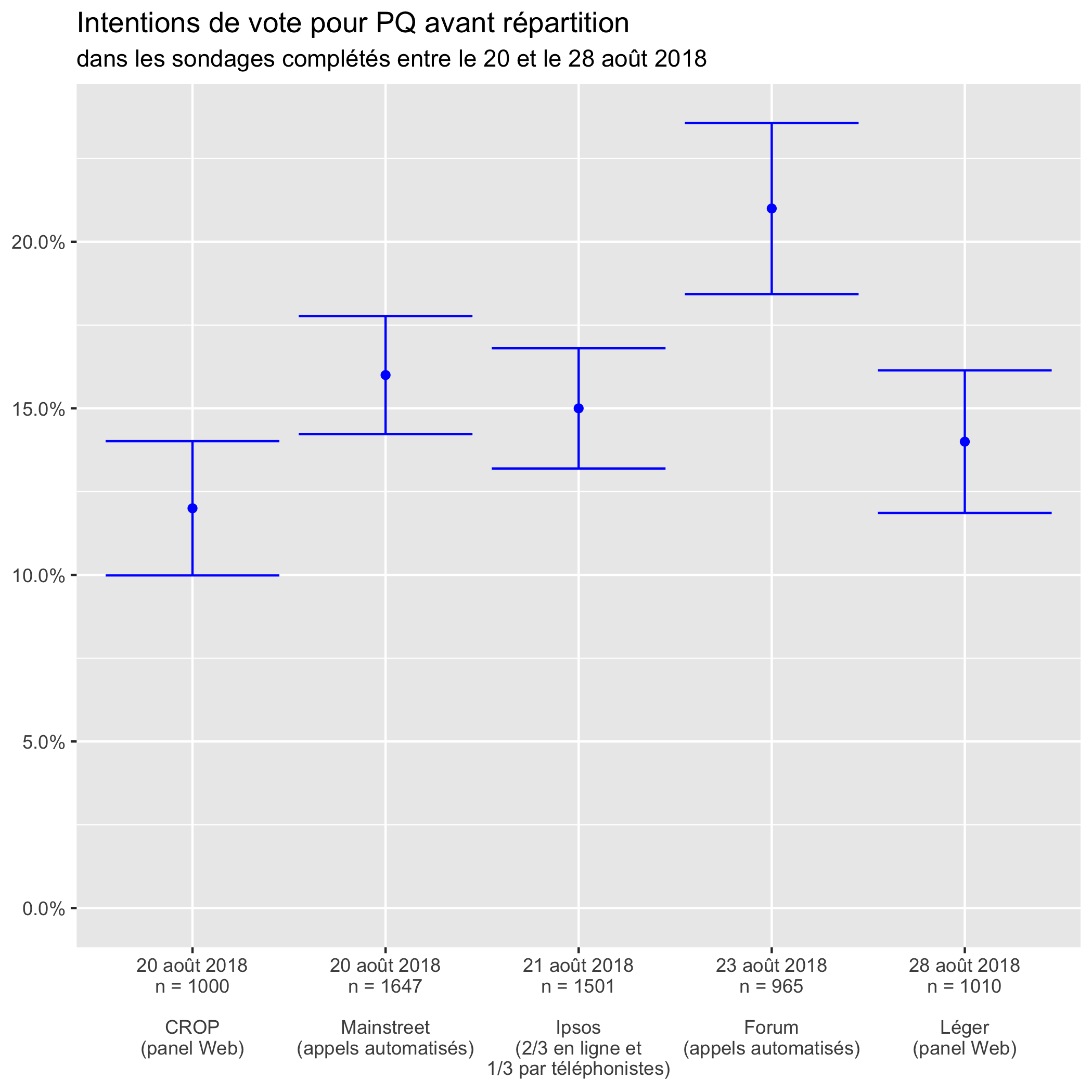
Quant au Parti libéral, c’est CROP qui le place anormalement haut.
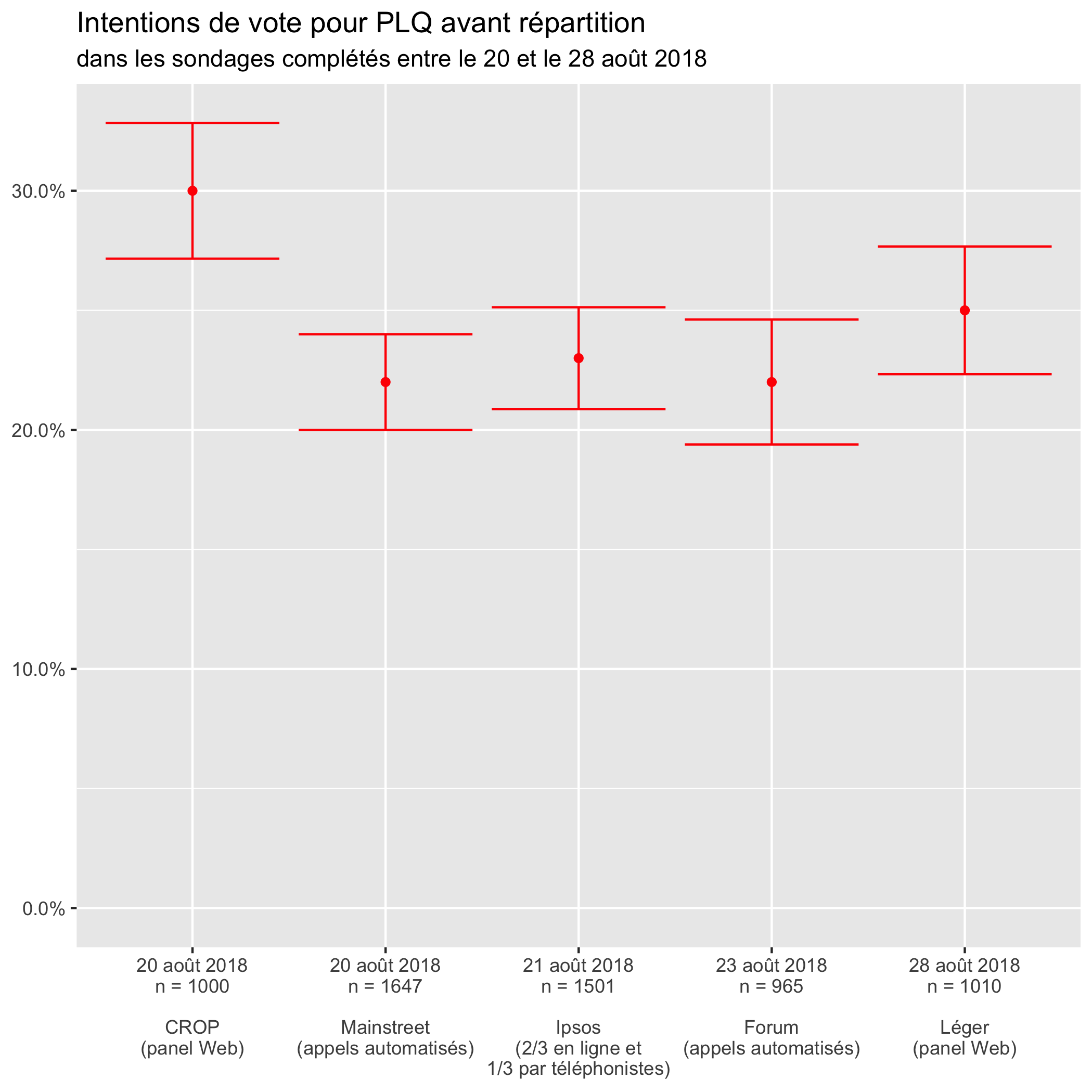
On va donc surveiller de près l’évolution des différences entre les intentions de vote mesurées par les différentes maisons de sondage. Elles ne semblent toutefois importantes que pour déterminer la composition de l’Assemblée nationale puisque l’identité du gouvernement semble déjà déterminée: le billet d’hier sur Too Close To Call s’intitule «La CAQ a plus de 99% de chances de gagner!» (toujours si l’élection se tenait aujourd’hui).
Données sources
Vous pouvez consulter le tableur qui a permis de faire les graphiques sur Google Spreadsheets.
Notes
- Je n’utilise pas les dernières données payantes de Mainstreet parce que je ne veux utiliser que des données publiques pour que vous puissiez vérifier et reproduire mes analyses à votre guise.
- Je n’ai toujours pas trouvé comment faire disparaître la décimale dans les étiquettes sur l’axe des y, et ça me rend un peu folle.
Bonjour
Comme je l’ai mentionné, l’erreur d’observation est plus importante que l’erreur statistique. Il est d’autre part abusif d’utiliser la théorie statistique lorsqu’elle ne s’applique pas. Je vous rappelle également qu’en statistique un gros échantillon est un échantillon de 30 individus et plus. Il me semble qu’il n’y a pas d’autres façons d’expliquer ces variations qu’en examinant la composition des différentes échantillons de 18-34.
Bonne journée